Reimagining Kernel Generation at the PTX Layer: An LLM System Learning from DSLs to Outperform Them
TL;DR
We built a hybrid system where program analysis and LLMs work together to transform and optimize PTX. By operating and reasoning at the shared PTX layer across DSLs (e.g. Triton, TileLang, ThunderKittens, CUTLASS), our system learns and combines optimizations to generate kernels that outperform all individual DSLs.
Background
PTX sits at the boundary between high-level code and actual GPU execution and is one of the hardest layers to work with directly. It is a foundational layer in the CUDA programming stack to which programs compile. Experts rely on manually inspecting PTX traces to understand performance, and in the most critical paths, they write inline PTX by hand to squeeze out every last bit of performance.
For a long time, this layer was out of reach for LLMs. PTX is low-level, massive, and requires extreme precision. A single kernel can span hundreds of thousands of tokens; understanding or modifying it means tracking dependencies across hundreds or thousands of instructions, where a single incorrect token can break the entire program. Earlier models simply couldn’t handle the context length or the reliability required. Recent advances (longer context windows and better semantic reasoning) have started to help, but LLMs alone still fall short.
System Overview
We have built a hybrid system where program analysis and LLMs work together to transform and interpret PTX. Our program analysis tool extracts and organizes the underlying structure while jointly working with LLMs to compress PTX into a more tractable representation. On top of that foundation, LLMs do what they’re uniquely good at: surfacing and learning higher-level patterns, intent, and hardware-specific behaviors. Reading and learning from PTX code is not something an LLM could do on its own and not something traditional program analysis could do either, but together, this system opens up a new way of understanding and optimizing GPU code.
One of the most exciting applications is a universal optimization layer across DSLs. Today’s DSLs (e.g. Triton, TileLang, ThunderKittens, CUTLASS) offer different abstractions and tradeoffs, but they’re opaque. They don’t tell you why one DSL outperforms another, but they can all compile down to emit PTX. By working at that shared layer, we can analyze and compare them directly. This lets us systematically capture best practices across ecosystems, produce highly optimized kernels that go beyond any single DSL, and continually adapt as new hardware instructions emerge. Instead of choosing between DSLs, we can learn from all of them. The result is generated kernels that combine the best optimizations and outperform all the individual DSLs.
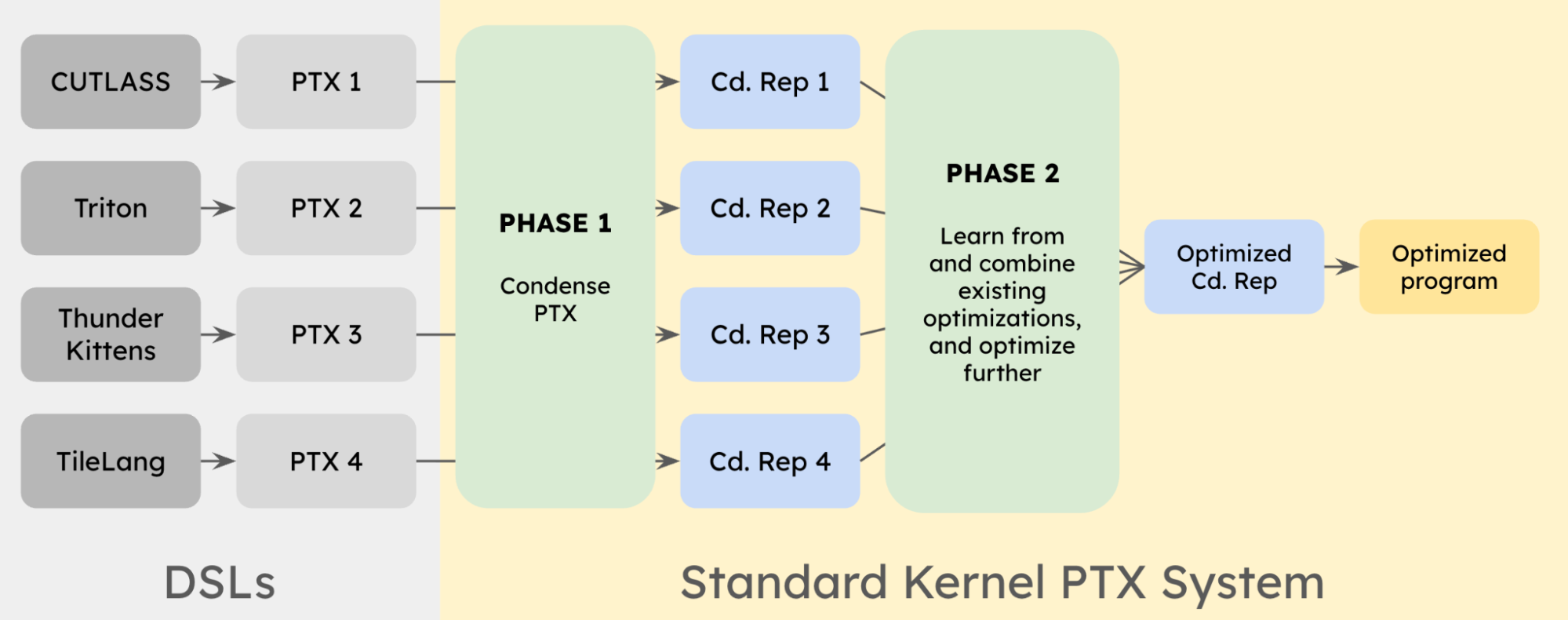
We start with different DSLs (CUTLASS, Triton, ThunderKittens, TileLang); each of these generates its own PTX, often with very different structures and optimization strategies baked in. These PTX programs are the low-level representations where performance actually emerges, but they are too large and unstructured to work with directly.
Phase 1: Condense PTX
We apply our hybrid program analysis + LLM system to each PTX independently. Program analysis and the LLM together extract structure and compress this into a more compact and tractable “condensed representation.” This gives us a set of condensed representations (Cd. Rep 1–4) all expressed in the same underlying form that is readable yet doesn't impose optimization constraints like a higher-level representation, which allows us to compare implementations.
Phase 2: Learn and combine.
Once everything is in this shared representation, we can operate across kernels. The system looks at multiple implementations of the same operation (e.g., GEMM or RMSNorm), identifies patterns, and combines the best ideas from each. This includes things like instruction selection, tiling strategies, memory movement patterns, and use of hardware-specific features.
Because this happens at the PTX level, we’re not constrained by any single DSL’s abstractions –– we can directly mix and refine optimizations that were previously siloed. The result is an optimized program in the condensed representation, which can then be materialized back into a final program. This output is often better than any single input DSL implementation, because it captures cross-DSL best practices and pushes them further. Over time, this evolves into a powerful and ever-growing repository of optimizations and knowledge base of newest hardware features that can be systematically applied to unlock new levels of performance.
DSL Experiments
For the purposes of this blog, we focus on two common kernels: RMSNorm and GEMM. For RMSNorm, we compare implementations across Triton, TileLang, and ThunderKittens. For GEMM, we include the same set and add CUTLASS as a strong baseline. We evaluate each kernel at two sizes (1024x1024 and 4096x4096) to capture optimizations at different sizes. All experiments run on an H100 GPU. Timing done with 50 warmup runs followed by averaging over 1000 trials.
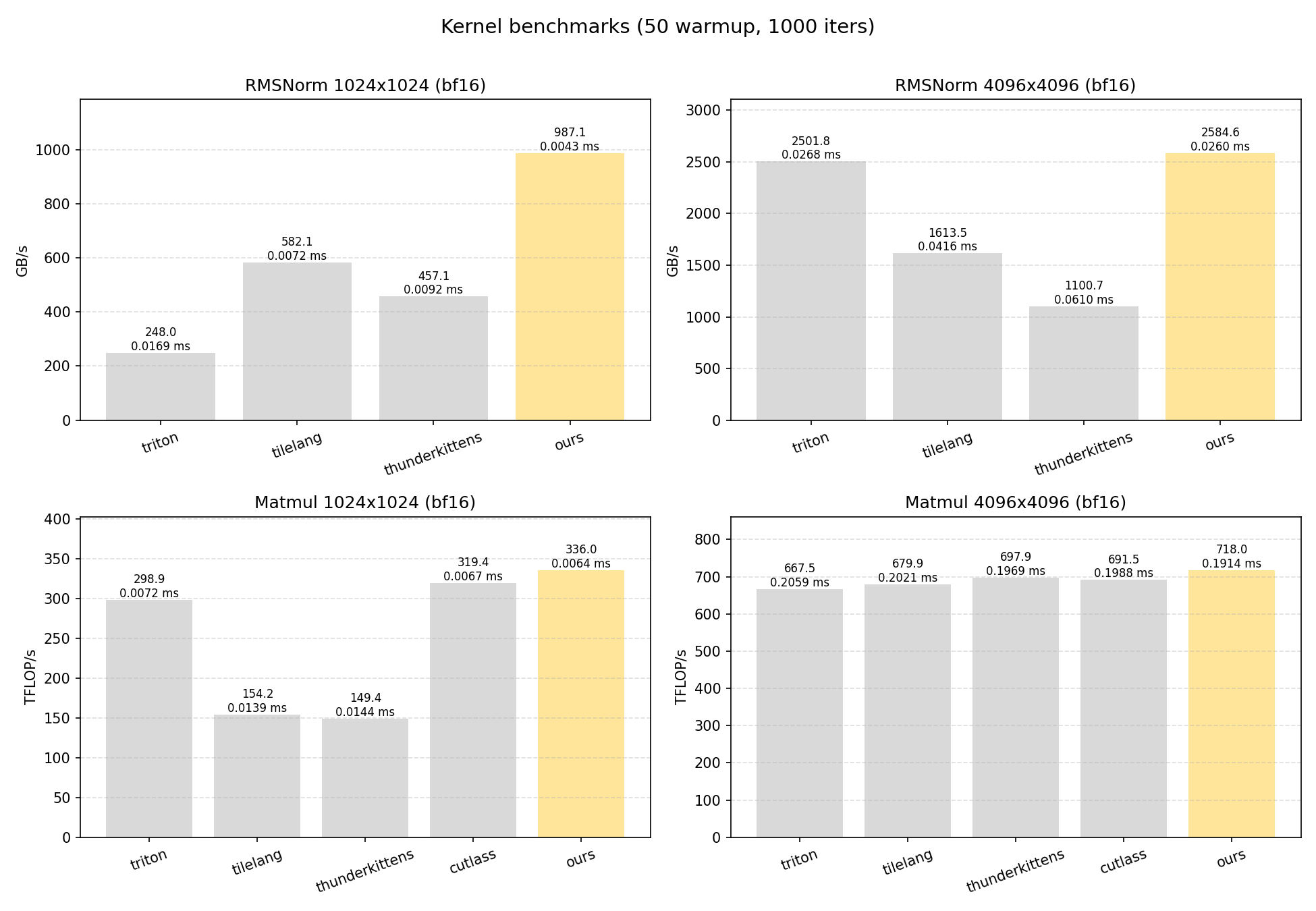
We got some pretty promising results from this system:
- RMSNorm-1024 is consistently faster than the fastest baseline (TileLang) by ~67%
- RMSNorm-4096 is consistently faster than the fastest baseline (Triton) by ~3%
- Matmul-1024 is consistently faster than the fastest baseline (CUTLASS) by ~5%
- Matmul-4096 is already highly optimized, and small fluctuations can shift rankings across runs, making evaluation more subtle. CUTLASS, ThunderKittens, and our kernel perform very closely: over 10 trials, our kernel placed first 5 times, CUTLASS 3, and ThunderKittens 2. We present a representative run where our kernel leads, but the more robust takeaway is that all three are tightly competitive.
Here are two example optimization trajectories for Matmul-1024 and RMSNorm-1024, demonstrating learning optimization ideas from multiple DSLs. Notably, we gain performance by working below the abstractions of the DSLs, as many of these optimization implementations cannot be expressed directly in some of the parent DSLs.
Matmul-1024
Starting from a CUTLASS-style kernel (8-stage pipeline, 1 producer/1 consumer warpgroup, tensor-core MMA, swizzled shared-memory layout, and a single-group pipeline), the speedups come from: a custom no-C-load epilogue that writes a fully swizzled output tile to shared memory and issues a single bulk store (replacing the baseline C-load path); improved L2 behavior via cache hints on bulk loads (idea from TileLang and ThunderKittens); batching two K-tiles per MMA group to reduce synchronization overhead without lowering tensor-core utilization; and reducing barrier traffic using a count-based arrive scheme (idea from ThunderKittens), plus a small register increase to ease scheduling
RMSNorm-1024
Starting from a TileLang-style skeleton with warp-specialized compute/memory roles, TMA bulk loads withmbarriersynchronization, XOR-swizzled shared memory, and shared weight reuse (idea from ThunderKittens), the speedups come from reducing compute-warp register usage to increase occupancy and hide memory stalls; simplifying the cross-warp reduction using mostly in-register shuffles to minimize synchronization; and using f32 accumulation and normalization with efficient bf16 packing (idea from Triton).
Disclaimer
We do not intend this post to be a comparison of DSLs, since we do not claim expertise in all the individual languages we test on. We start from official repository examples, apply minimal modifications, and in some cases run autotuning to select reasonable configurations for each shape. Adaptations are done on a best-effort basis. Additionally, even if a more optimal DSL configuration exists, our approach remains applicable, as we can extract the generated PTX from those implementations. Sources below: